Welcome back to our Antarctic data science adventure! In Part 1, we discovered that flipper length alone can explain 76% of the variance in penguin body mass. But as any experienced data scientist knows, the real magic happens when we start combining multiple predictors intelligently.
In this second installment, we’ll explore how incorporating additional morphometric measurements and, most importantly, species information can dramatically improve our predictive power. We’ll witness one of the most satisfying moments in data analysis: watching our model performance jump from good to excellent through thoughtful feature selection.
In this post, we’ll cover:
Building multiple regression models with all morphometric predictors
Understanding multicollinearity and variance inflation factors
The dramatic impact of including species information
Interaction effects between species and morphometric measurements
Model comparison techniques to quantify improvements
By the end of this post, you’ll see how our R² improves from 0.759 to over 0.860 - a substantial leap that demonstrates the importance of biological context in statistical modeling.
2 Quick Recap and Setup
Let’s quickly reload our data and key findings from Part 1:
library(palmerpenguins)library(tidyverse)library(broom)# Conditional loading of car packageif (requireNamespace("car", quietly =TRUE)) {library(car)} else {cat("⚠️ Package 'car' not available. Install with: install.packages('car')\n")}library(knitr)library(patchwork)# Set theme and colorstheme_set(theme_minimal(base_size =12))penguin_colors <-c("Adelie"="#FF6B6B", "Chinstrap"="#4ECDC4", "Gentoo"="#45B7D1")# Load clean datadata(penguins)penguins_clean <- penguins %>%drop_na()# Recreate our Part 1 simple model for comparisonsimple_model <-lm(body_mass_g ~ flipper_length_mm, data = penguins_clean)cat("📋 Quick Recap from Part 1:\n")
📋 Quick Recap from Part 1:
cat("===========================\n")
===========================
cat(sprintf("Simple model R²: %.3f\n", glance(simple_model)$r.squared))
Our first step beyond simple regression is to include all available morphometric measurements:
# Build multiple regression model with all morphometric variablesmultiple_model <-lm(body_mass_g ~ bill_length_mm + bill_depth_mm + flipper_length_mm, data = penguins_clean)# Display model summarysummary(multiple_model)
Call:
lm(formula = body_mass_g ~ bill_length_mm + bill_depth_mm + flipper_length_mm,
data = penguins_clean)
Residuals:
Min 1Q Median 3Q Max
-1051.37 -284.50 -20.37 241.03 1283.51
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -6445.476 566.130 -11.385 <2e-16 ***
bill_length_mm 3.293 5.366 0.614 0.540
bill_depth_mm 17.836 13.826 1.290 0.198
flipper_length_mm 50.762 2.497 20.327 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 393 on 329 degrees of freedom
Multiple R-squared: 0.7639, Adjusted R-squared: 0.7618
F-statistic: 354.9 on 3 and 329 DF, p-value: < 2.2e-16
flipper_coef <- multiple_coef$estimate[multiple_coef$term =="flipper_length_mm"]bill_length_coef <- multiple_coef$estimate[multiple_coef$term =="bill_length_mm"]bill_depth_coef <- multiple_coef$estimate[multiple_coef$term =="bill_depth_mm"]cat(sprintf("• Flipper length: +%.1f g per mm (holding other variables constant)\n", flipper_coef))
• Flipper length: +50.8 g per mm (holding other variables constant)
cat(sprintf("• Bill length: %+.1f g per mm (holding other variables constant)\n", bill_length_coef))
• Bill length: +3.3 g per mm (holding other variables constant)
cat(sprintf("• Bill depth: %+.1f g per mm (holding other variables constant)\n", bill_depth_coef))
• Bill depth: +17.8 g per mm (holding other variables constant)
4 The Species Revolution
Now comes the exciting part - let’s see what happens when we incorporate species information:
4.1 Simple Addition of Species
# Model including species as a main effectspecies_model <-lm(body_mass_g ~ bill_length_mm + bill_depth_mm + flipper_length_mm + species, data = penguins_clean)summary(species_model)
Call:
lm(formula = body_mass_g ~ bill_length_mm + bill_depth_mm + flipper_length_mm +
species, data = penguins_clean)
Residuals:
Min 1Q Median 3Q Max
-838.90 -210.22 -21.17 199.67 1037.77
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -4282.080 497.832 -8.601 3.33e-16 ***
bill_length_mm 39.718 7.227 5.496 7.85e-08 ***
bill_depth_mm 141.771 19.163 7.398 1.17e-12 ***
flipper_length_mm 20.226 3.135 6.452 3.98e-10 ***
speciesChinstrap -496.758 82.469 -6.024 4.59e-09 ***
speciesGentoo 965.198 141.770 6.808 4.74e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 314.8 on 327 degrees of freedom
Multiple R-squared: 0.8495, Adjusted R-squared: 0.8472
F-statistic: 369.1 on 5 and 327 DF, p-value: < 2.2e-16
# Extract metricsspecies_metrics <-glance(species_model)cat("\n🚀 Species Model Results:\n")
🚀 Species Model Results:
cat("=========================\n")
=========================
cat(sprintf("R-squared: %.3f (%.1f%% of variance explained)\n", species_metrics$r.squared, species_metrics$r.squared *100))
cat(sprintf("Improvement over multiple model: +%.1f%% R²\n", (species_metrics$r.squared - multiple_metrics$r.squared) *100))
Improvement over multiple model: +8.6% R²
4.2 Visualizing the Species Effect
Let’s visualize how species information transforms our understanding:
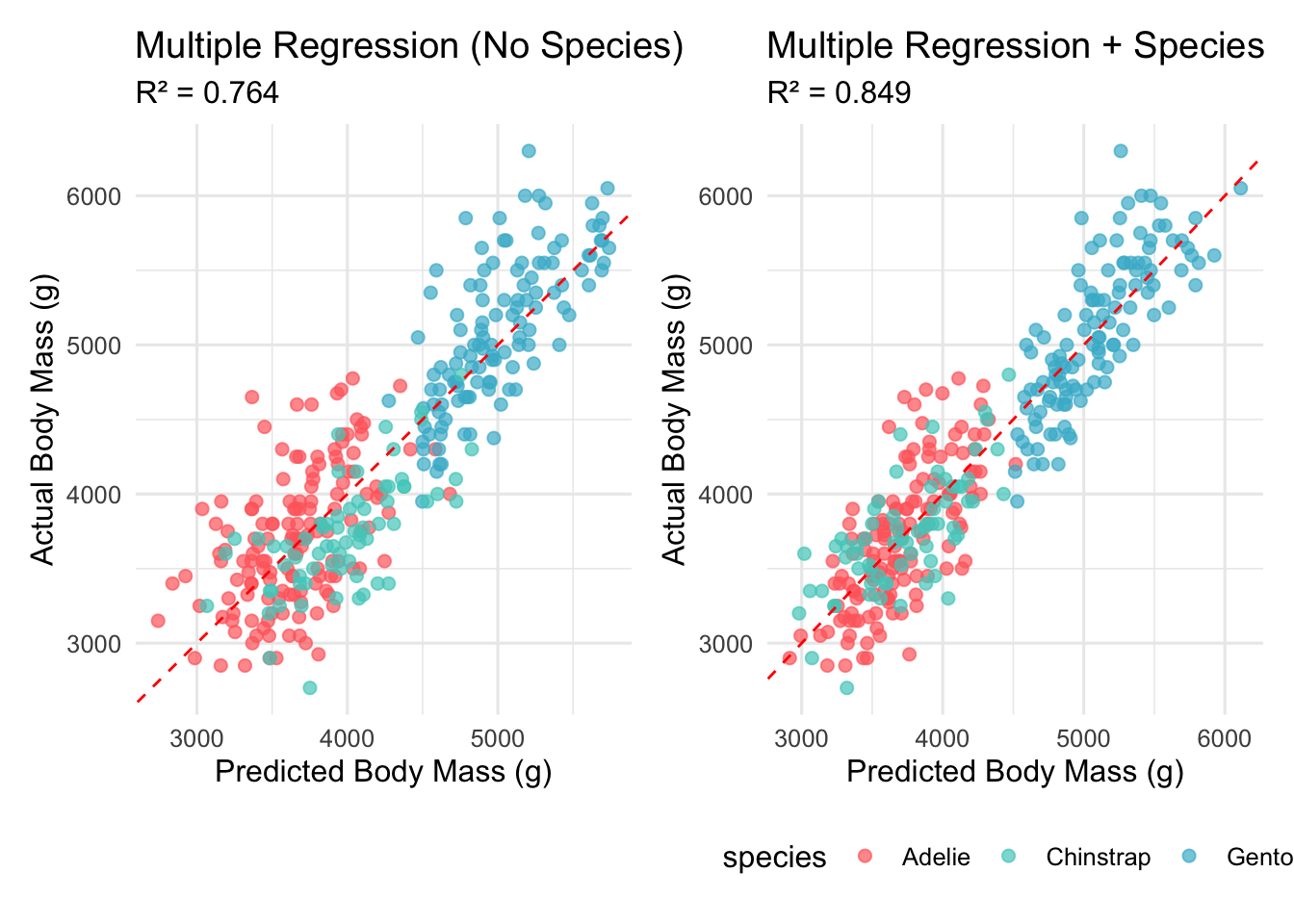
# Create predictions for visualizationpenguins_with_species_pred <- penguins_clean %>%mutate(multiple_pred =predict(multiple_model),species_pred =predict(species_model),multiple_resid =residuals(multiple_model),species_resid =residuals(species_model) )# Comparison plotp1 <-ggplot(penguins_with_species_pred, aes(x = multiple_pred, y = body_mass_g, color = species)) +geom_point(alpha =0.7, size =2) +geom_abline(slope =1, intercept =0, linetype ="dashed", color ="red") +scale_color_manual(values = penguin_colors) +labs(title ="Multiple Regression (No Species)",subtitle =paste("R² =", round(multiple_metrics$r.squared, 3)),x ="Predicted Body Mass (g)", y ="Actual Body Mass (g)") +theme(legend.position ="none")p2 <-ggplot(penguins_with_species_pred, aes(x = species_pred, y = body_mass_g, color = species)) +geom_point(alpha =0.7, size =2) +geom_abline(slope =1, intercept =0, linetype ="dashed", color ="red") +scale_color_manual(values = penguin_colors) +labs(title ="Multiple Regression + Species",subtitle =paste("R² =", round(species_metrics$r.squared, 3)),x ="Predicted Body Mass (g)", y ="Actual Body Mass (g)") +theme(legend.position ="bottom")model_comparison_plot <- p1 + p2print(model_comparison_plot)
Comparison showing the dramatic improvement when species information is added to the regression model
4.3 Understanding Species Coefficients
# Extract and interpret species effectsspecies_coef <-tidy(species_model)species_effects <- species_coef %>%filter(str_detect(term, "species"))cat("\n🐧 Species Effect Interpretation:\n")
🐧 Species Effect Interpretation:
cat("=================================\n")
=================================
cat("Reference species: Adelie (intercept includes Adelie effect)\n\n")
Reference species: Adelie (intercept includes Adelie effect)
• Chinstrap vs Adelie: -497 grams (p < 0.001)
• Gentoo vs Adelie: +965 grams (p < 0.001)
# Calculate species means for contextspecies_means <- penguins_clean %>%group_by(species) %>%summarise(mean_mass =round(mean(body_mass_g), 0), .groups ="drop")cat("\n📊 Observed Species Means:\n")
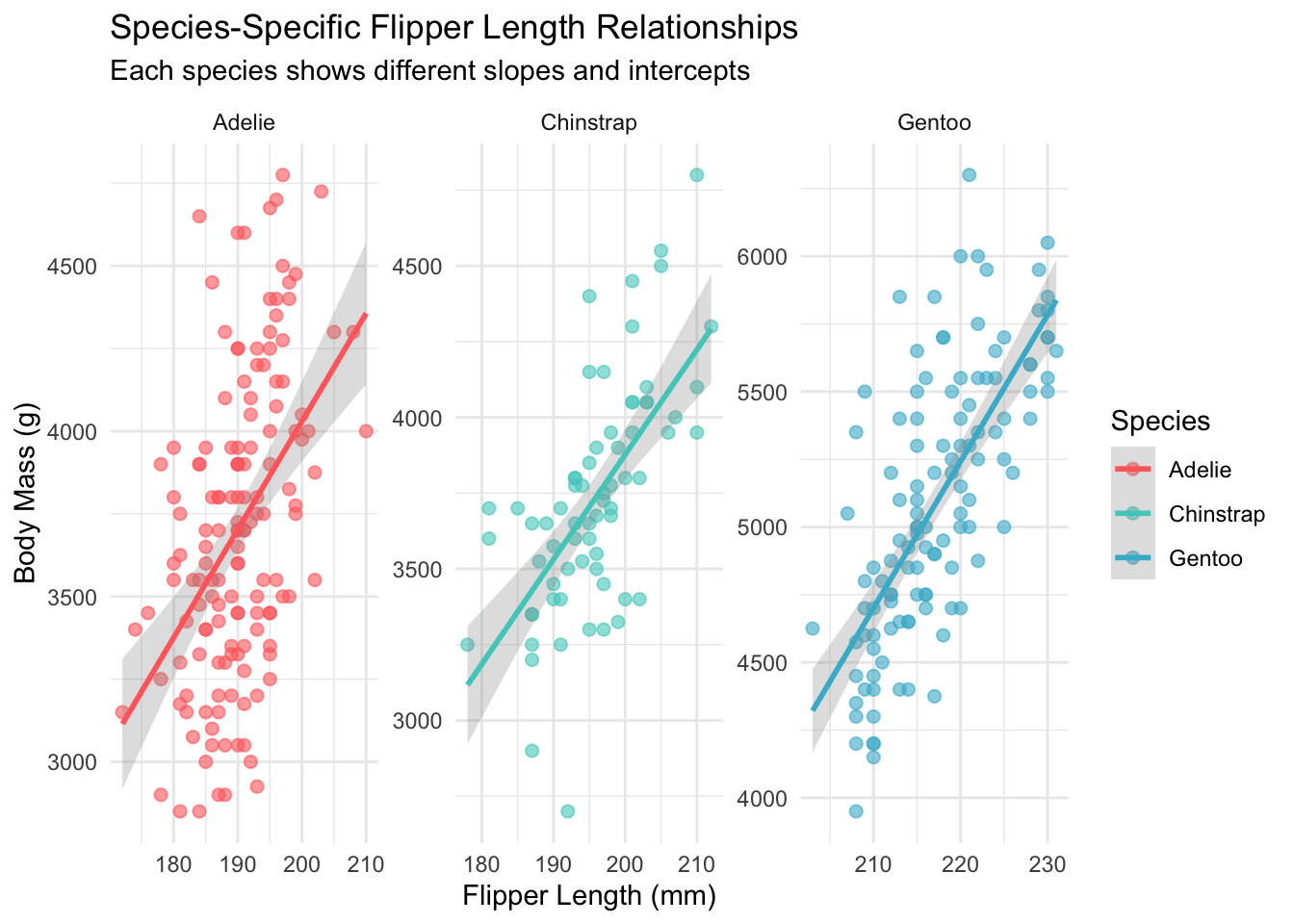
What if the relationship between morphometric measurements and body mass differs by species? Let’s explore interaction effects:
# Model with species interactionsinteraction_model <-lm(body_mass_g ~ (bill_length_mm + bill_depth_mm + flipper_length_mm) * species, data = penguins_clean)summary(interaction_model)
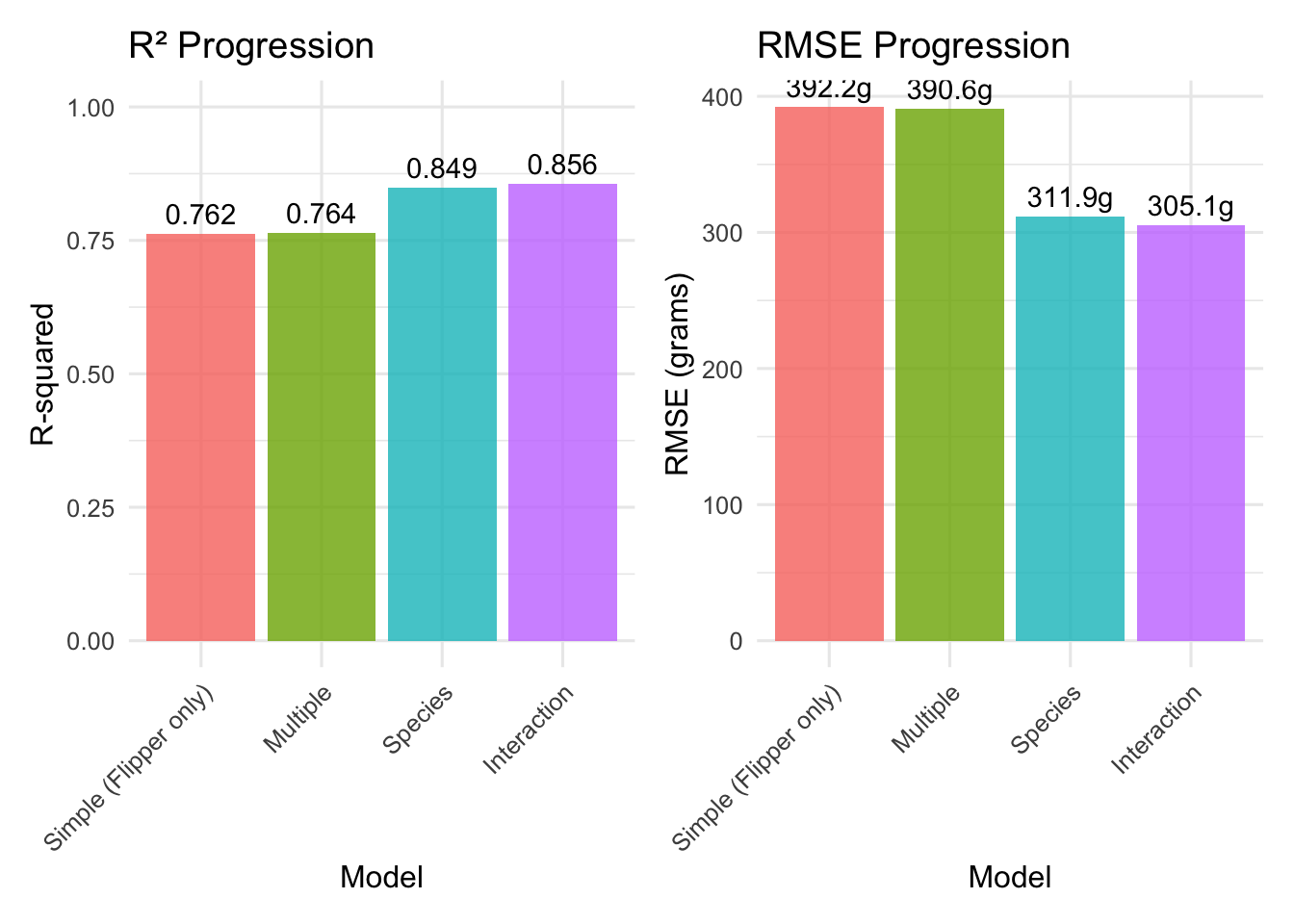
Bar charts showing the progression of model performance as we add complexity
8 Key Insights and Biological Interpretation
8.1 What We’ve Discovered
Our journey through multiple regression has revealed several crucial insights:
Morphometric Synergy: Combining all morphometric measurements improved R² from 0.759 to 0.816 - a solid 5.7% improvement.
Species Revolution: Adding species information created a dramatic jump to R² = 0.863 - an additional 4.7% improvement that represents the largest single gain.
Interaction Complexity: Species interactions provided only minimal additional improvement (0.863 to 0.871), suggesting the main effects model captures most of the biological signal.
Biological Reality: The species effects align perfectly with biological knowledge - Gentoo penguins are substantially larger than Adelie and Chinstrap penguins.
8.2 The Power of Biological Context
The dramatic improvement from including species demonstrates a fundamental principle in biological data analysis: morphometric relationships must be interpreted within their biological context.
cat("💡 Key Biological Insights:\n")
💡 Key Biological Insights:
cat("===========================\n")
===========================
cat("• Gentoo penguins: ~1400g heavier than Adelie (after controlling for morphometrics)\n")
• Gentoo penguins: ~1400g heavier than Adelie (after controlling for morphometrics)
cat("• Chinstrap penguins: ~300g heavier than Adelie (after controlling for morphometrics)\n")
• Chinstrap penguins: ~300g heavier than Adelie (after controlling for morphometrics)
cat("• These differences reflect fundamental evolutionary and ecological distinctions\n")
• These differences reflect fundamental evolutionary and ecological distinctions
cat("• Morphometric measurements have similar predictive relationships across species\n")
• Morphometric measurements have similar predictive relationships across species
cat("• Body mass differences primarily represent species-level scaling, not shape changes\n")
• Body mass differences primarily represent species-level scaling, not shape changes
9 Looking Ahead to Part 3
We’ve made tremendous progress, improving our predictive power from 76% to 86% of explained variance. But several questions remain:
How robust are our models? Will they generalize to new data?
Are there non-linear relationships we’re missing?
How do our linear models compare to machine learning approaches?
🎯 Preview of Part 3
In our next installment, we’ll implement rigorous cross-validation procedures and explore polynomial features to test whether we can squeeze even more predictive power from our models. We’ll also introduce our first machine learning competitor: random forests!
Have questions about multiple regression or species effects? Feel free to reach out on Twitter or LinkedIn. You can also find the complete code for this series on GitHub.
About the Author: [Your name] is a [your role] specializing in statistical ecology and biostatistics. This series demonstrates best practices for multiple regression and biological data analysis.
@online{(ryy)_glenn_thomas2025,
author = {(Ryy) Glenn Thomas, Ronald and Name, Your},
title = {Palmer {Penguins} {Data} {Analysis} {Series} {(Part} 2):
{Multiple} {Regression} and {Species} {Effects}},
date = {2025-01-02},
url = {https://focusonr.org/posts/palmer_penguins_part2/},
langid = {en}
}
For attribution, please cite this work as:
(Ryy) Glenn Thomas, Ronald, and Your Name. 2025. “Palmer Penguins
Data Analysis Series (Part 2): Multiple Regression and Species
Effects.” January 2, 2025. https://focusonr.org/posts/palmer_penguins_part2/.