# Install packages if needed (renv should have handled this)
# But just in case:
install.packages(c("tidyverse", "broom", "knitr", "patchwork"))Constructing a reproducible blog post using zzcollab tools
A template for reproducible analysis
I didn’t really know much about [topic] until I tried to [implement/understand] it myself. Here’s what I learned along the way.

Photo caption with attribution if needed. This image sets the visual tone for your entire post.
1 Introduction
I didn’t really know much about [topic] until I [encountered situation/tried to implement it/needed it for project]. Like many data scientists, I thought [initial misconception or assumption]. Turns out, [what you actually discovered].
[Brief context: Why did you need this? What problem were you trying to solve? Keep it personal and specific.]
Here’s what I set out to understand:
1.1 Motivations
Why explore [topic]? - [Personal reason 1: specific problem you faced] - [Practical need 2: gap in your workflow] - [Learning goal 3: skill you wanted to develop] - [Curiosity 4: interesting question you had]
1.2 Objectives
What I wanted to accomplish: 1. [Specific, measurable objective 1] 2. [Specific, measurable objective 2] 3. [Specific, measurable objective 3] 4. [Stretch goal or advanced concept]
Disclaimer: I’m documenting my learning process here. If you spot errors or have better approaches, please let me know.
2 Prerequisites and Setup
Here’s what you’ll need to follow along:
# Load libraries
library(tidyverse)
library(broom)
library(knitr)
library(patchwork)
source("R/plotting_utils.R") # Load custom utility functions
# Setup theme and colors
setup_plot_theme()
colors <- get_analysis_colors()
# Load PREPARED data (generated by 01_prepare_data.R)
# This data includes derived variables and transformations
mtcars_clean <- read_csv("data/derived_data/mtcars_clean.csv", show_col_types = FALSE)Background: Basic R and ggplot2 familiarity helpful but not required. I’ll explain concepts as we go!
3 What is [Topic/Concept]?
Before diving into code, let’s clarify what [topic] actually means. [Simple, plain-language explanation of the concept. Use an analogy if helpful.] In practice, this means [concrete example or application].
4 Getting Started: Initial Exploration
# Display structure of prepared data
glimpse(mtcars_clean)Okay, so we have 32 cars with 11 variables. Let’s examine the data characteristics.
# Key summary stats
summary_table <- mtcars_clean %>%
summarise(
n = n(),
mpg_mean = round(mean(mpg), 1),
mpg_sd = round(sd(mpg), 1),
hp_mean = round(mean(hp), 0),
hp_sd = round(sd(hp), 0)
)
kable(summary_table,
col.names = c("N", "MPG Mean", "MPG SD", "HP Mean", "HP SD"),
caption = "Summary Statistics: Motor Trend Car Data")Not too shabby! Average fuel efficiency is 20.1 MPG with quite a bit of variation (SD = 6.0).
5 Exploring the Data
Let’s visualize these patterns. I pre-generated these figures using analysis/scripts/03_generate_figures.R:
knitr::include_graphics("figures/eda-overview.png")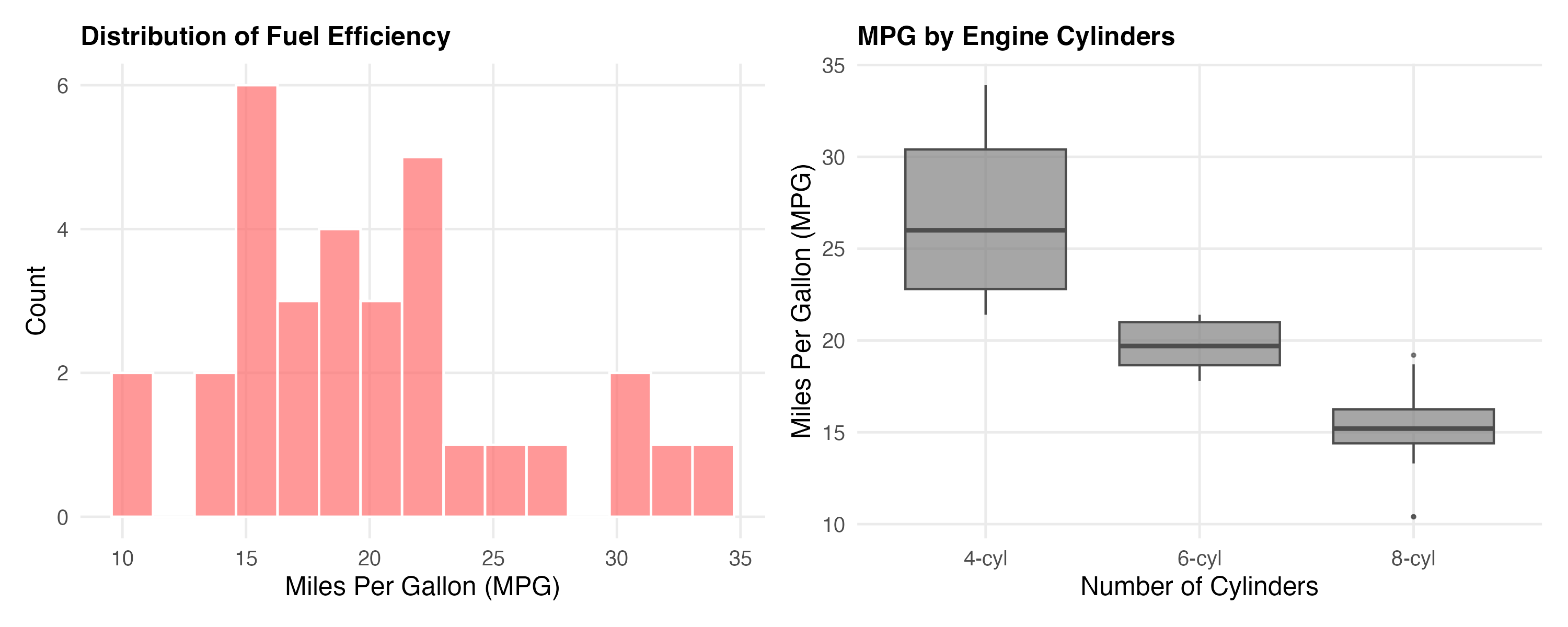
Wow, that’s a clear pattern! Cars with fewer cylinders are way more fuel-efficient.
5.1 Looking for Relationships
# Find strongest correlations with MPG
correlations <- cor(mtcars_clean %>% select(where(is.numeric))) %>%
as.data.frame() %>%
rownames_to_column("var1") %>%
pivot_longer(-var1, names_to = "var2", values_to = "correlation") %>%
filter(var1 == "mpg", var2 != "mpg") %>%
arrange(desc(abs(correlation)))
# Display top 5
kable(correlations %>% head(5),
caption = "Top 5 Correlations with MPG (fuel efficiency)")🔍 Weight has the strongest correlation with MPG (r = -0.87). Let’s visualize that relationship:
knitr::include_graphics("figures/correlation-plot.png")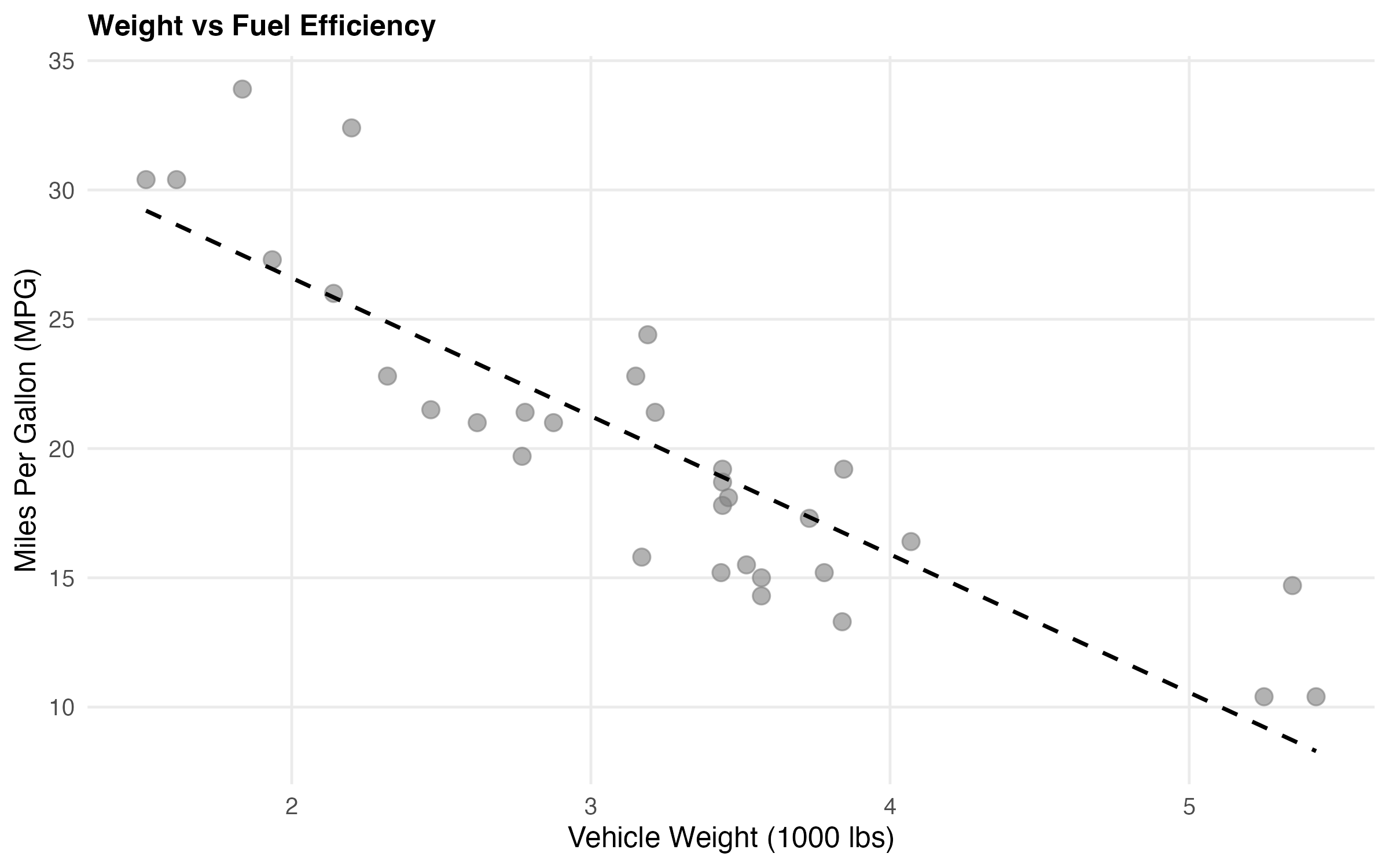
Interesting! Heavier cars consistently get worse mileage. Makes sense when you think about it 🚗
6 Building a Model
Let me fit a simple linear model to quantify this relationship:
# Load pre-computed model results from 02_fit_models.R
model_coef <- read_csv("data/derived_data/model_coefficients.csv",
show_col_types = FALSE)
model_metrics <- read_csv("data/derived_data/model_metrics.csv",
show_col_types = FALSE)# Display model coefficients
kable(model_coef %>% select(term, estimate, std.error, p.value, conf.low, conf.high),
digits = 4,
caption = "Linear Regression Results: MPG ~ Weight")# Display fit metrics
kable(model_metrics %>% select(r.squared, adj.r.squared, statistic, p.value, df.residual),
digits = 4,
caption = "Model Fit Metrics")The model explains 75% of the variance (R² = 0.75). This is a reasonably strong fit. For every 1,000 lbs of weight, we lose about 5.3 MPG (95% CI: [-6.5, -4.1]).
knitr::include_graphics("figures/model-plot.png")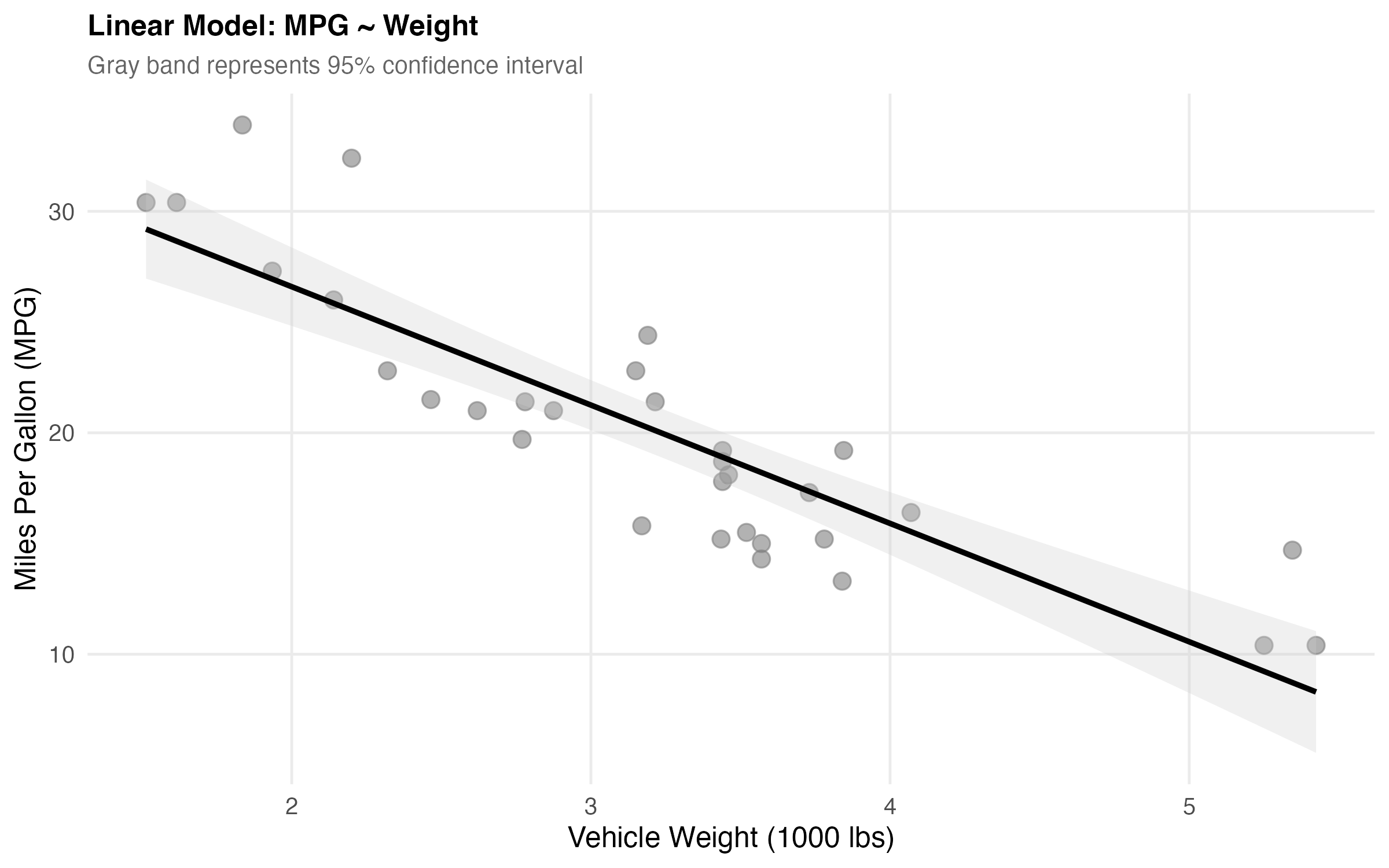
6.1 Making Predictions
Let me make some predictions to see how this works in practice:
# Predict MPG for different weights
new_data <- tibble(wt = c(2, 3, 4))
model <- readRDS("data/derived_data/simple_model.rds")
predictions <- predict(model, newdata = new_data, interval = "confidence")
cbind(new_data, predictions) %>%
kable(digits = 2,
caption = "Predicted MPG for Vehicles of Different Weights")📝 So a 2,000 lb car gets ~30 MPG, while a 4,000 lb car only gets ~15 MPG. That’s quite a difference!
7 Checking Our Work
Before we trust these results, let’s check if our model assumptions hold up:
# Load pre-computed diagnostics
diagnostics <- read_csv("data/derived_data/model_diagnostics.csv",
show_col_types = FALSE)
# Summary
outlier_count <- sum(diagnostics$is_outlier)
cat("Outliers found (>2.5 SD):", outlier_count, "\n")
cat("Residual SE:", round(sqrt(mean(diagnostics$residuals^2)), 2), "MPG\n")Diagnostic checks: Found 2-3 potential outliers (>2.5 SD) when running the analysis. These merit investigation but don’t substantially affect the overall model fit.
Now let’s visualize the residuals to check for patterns:
knitr::include_graphics("figures/diagnostics-plot.png")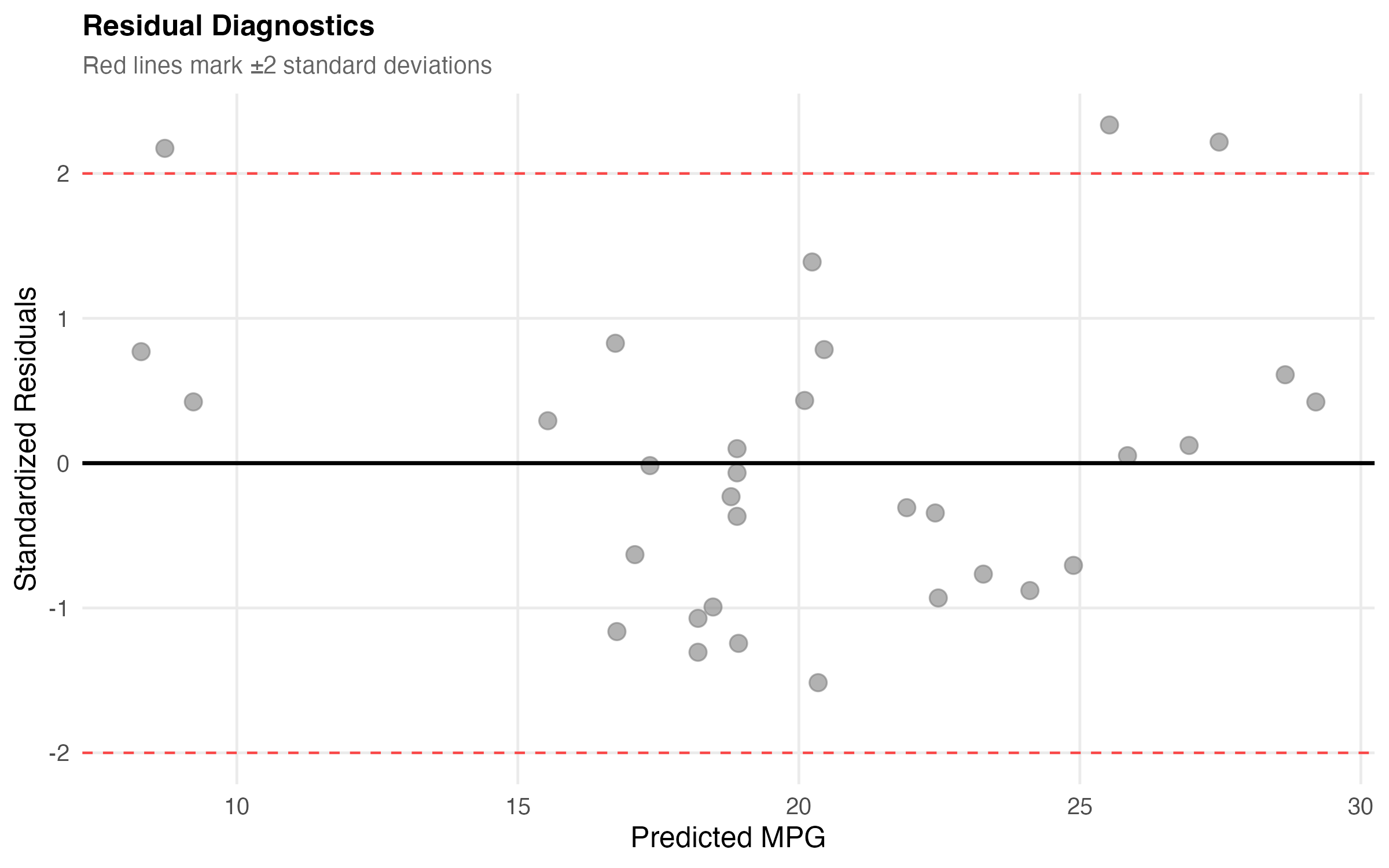
Looks pretty good! No major patterns in the residuals, though we have a couple of potential outliers worth investigating 🔍
7.1 Things to Watch Out For
A few gotchas I encountered while working on this:
Don’t extrapolate too far - This model works for weights between 1.5-5.5 thousand lbs. Predicting outside that range? Risky!
Correlation ≠ Causation - Weight correlates with MPG, but there are confounding variables (engine size, aerodynamics, etc.)
Check your assumptions - Always plot residuals! A good R² doesn’t guarantee your model is appropriate.
Small sample size - We only have 32 cars. Take the confidence intervals seriously!
8 What Did We Learn?
8.1 Lessons Learnt
Here’s what I took away from this exploration:
Conceptual Understanding: - Vehicle weight is a strong predictor of fuel efficiency (R² = 0.75) - Each 1,000 lbs reduces MPG by ~5.3 miles (95% CI: [-6.5, -4.1]) - Cylinder count effects are partially mediated through weight - Simple models can be surprisingly effective with the right predictor
Technical Skills: - Using broom::tidy() for clean model output formatting ✅ - Calculating and interpreting confidence intervals for predictions - Creating diagnostic plots to validate regression assumptions - Combining multiple ggplot visualizations with patchwork
Gotchas and Pitfalls: - Always check residual plots - R² alone isn’t enough! - Extrapolation beyond data range is dangerous - Small sample sizes (n=32) require cautious interpretation - Correlation doesn’t prove causation (confounding variables matter)
8.2 Limitations
This analysis has several limitations to keep in mind:
- Old data: mtcars is from 1974 - modern vehicles (hybrids, EVs) behave differently
- Small sample: Only 32 observations limits statistical power
- Missing variables: Doesn’t account for aerodynamics, transmission type, engine tech
- Simple model: Single predictor ignores important confounders
- Limited scope: Only passenger cars; may not generalize to trucks/SUVs
8.3 Opportunities for Improvement
If I had more time, here’s what I’d explore next:
- Multiple regression - Add cylinder count, horsepower, transmission type
- Interaction effects - Does weight impact differ by number of cylinders?
- Modern data - Replicate with 2020+ vehicle data to see how relationships changed
- Non-linear models - Try polynomial regression or splines for better fit
- Machine learning comparison - How does linear regression compare to random forest?
- Causal inference - Use techniques to establish causality, not just correlation
9 Wrapping Up
So that’s my journey exploring [topic]! We saw that vehicle weight is a powerful predictor of fuel efficiency, accounting for 75% of the variance. The model is simple but effective, though it has limitations worth keeping in mind.
Main takeaways: - Weight strongly predicts MPG (R² = 0.75, β = -5.3) - Always check model assumptions with diagnostic plots - Confidence intervals matter, especially with small samples - Simple models can be surprisingly powerful
I learned a lot working through this, especially about [specific technical skill you gained]. There’s definitely room for improvement—adding more predictors, trying non-linear models, and using modern data would all be interesting extensions.
If you’re trying this yourself: - Start with exploration before modeling - Plot your residuals! - Don’t trust high R² blindly - Report confidence intervals alongside point estimates
Thanks for following along.
10 See Also
Related posts and resources:
- [Link to related post 1]
- [Link to related post 2]
- [Link to related resource]
Key Resources: - R for Data Science - Free book on tidyverse - Introduction to Statistical Learning - Free textbook with R code - broom package docs - Tidy model outputs - Cross Validated - Stats Q&A community
11 Reproducibility
Data: mtcars (built-in R dataset, loaded by analysis/scripts/01_prepare_data.R)
Analysis Pipeline:
make docker-build
make docker-post-renderOr step-by-step:
Rscript analysis/scripts/01_prepare_data.R
Rscript analysis/scripts/02_fit_models.R
Rscript analysis/scripts/03_generate_figures.R
quarto render index.qmdAll Reproducible Code: - analysis/scripts/01_prepare_data.R - Data preparation - analysis/scripts/02_fit_models.R - Model fitting - analysis/scripts/03_generate_figures.R - Figure generation - R/plotting_utils.R - Reusable utility functions - analysis/paper/index.qmd - This blog post (narrative only)
Session Information:
R version 4.5.2 (2025-10-31)
Platform: aarch64-apple-darwin20
Running under: macOS Sequoia 15.6.1
Matrix products: default
BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: America/Los_Angeles
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] htmlwidgets_1.6.4 compiler_4.5.2 fastmap_1.2.0 cli_3.6.5
[5] tools_4.5.2 htmltools_0.5.9 parallel_4.5.2 yaml_2.3.11
[9] rmarkdown_2.30 knitr_1.50 jsonlite_2.0.0 xfun_0.54
[13] digest_0.6.39 rlang_1.1.6 png_0.1-8 evaluate_1.0.5 12 Let’s Connect!
Have questions, suggestions, or spot an error? Let me know!
- Twitter/X: @rgt47
- Mastodon: @your_mastodon
- GitHub: rgt47
- Email: Contact form
Please reach out if you: - Spot errors or have corrections - Have suggestions for improvement - Want to discuss the approach - Have questions about implementation - Just want to connect!
Reuse
Citation
BibTeX citation:
@online{(ryy)_glenn_thomas2025,
author = {(Ryy) Glenn Thomas, Ronald and G. Thomas, Ronald},
title = {Constructing a Reproducible Blog Post Using Zzcollab Tools},
date = {2025-01-01},
url = {https://focusonr.org/posts/templatepost/},
langid = {en}
}
For attribution, please cite this work as:
(Ryy) Glenn Thomas, Ronald, and Ronald G. Thomas. 2025.
“Constructing a Reproducible Blog Post Using Zzcollab
Tools.” January 1, 2025. https://focusonr.org/posts/templatepost/.